Measuring Utility and Information Loss¶
SDC is a trade-off between risk of disclosure and loss of data utility and seeks to minimize the latter, while reducing the risk of disclosure to an acceptable level. Data utility in this context means the usefulness of the anonymized data for statistical analyses by end users as well as the validity of these analyses when performed on the anonymized data. Disclosure risk and its measurement are defined in the Section Measure Risk of this guide. In order to make a trade-off between minimizing disclosure risk and maximizing utility of data for end users, it is necessary to measure the utility of the data after anonymization and compare it with the utility of the original data. This section describes measures that can be used to compare the data utility before and after anonymization, or alternatively quantify the information loss. Information loss is the inverse of data utility: the larger the data utility after anonymization, the smaller the information loss.
Note
If the microdata to be anonymized is based on a sample, the data will incur a sampling error. Also other errors may be present in the data, such as nonresponse error.
Note
The methods discussed here only measure the information loss caused by the anonymization process relative to the original sample data and do not attempt to measure the error caused by other sources.
Ideally, the information loss is evaluated with respect to the needs and uses of the end users of the microdata. However, different end users of anonymized data may have very diverse uses for the released data and it might not be possible to collect an exhaustive list of these uses. Even if many uses can be identified, the characteristics in the data needed for these uses can be contradictory (e.g., one user needs a detailed geographical level whereas another is interested in a detailed age structure and does not need a detailed geographical structure). Nevertheless, as pointed out earlier, only one anonymized dataset can be released for each dataset and every type of release to avoid unintended disclosure. Releasing multiple anonymized datasets for different purposes may lead to unintended disclosure. [1] Therefore, it is not possible to anonymize and release a file tailored to each user’s needs.
Since collecting and taking into account all data uses is often impossible, we also look at general (or generic) information loss measures besides user- and data-specific information loss measures. These measures do not take into account the specific data use, but can be used as guiding measures for information loss and evaluating whether a dataset is still analytically valid after anonymization. The main idea for such measures is to compare records between the original and treated datasets and compare statistics computed from both datasets (HDFG12). Examples of such measures are the number of suppressions, number of changed values, changes in contingency tables and changes in mean and covariance matrices.
Many of the SDC methods discussed earlier are parametric, in the sense that their outcome depends on parameters chosen by the user. Examples are the cluster size for microaggregation (see the Section Microaggregation) or the importance vector in local suppression (see the Section Local suppression). Data utility and information loss measures are useful for choosing these parameters by comparing the impact of different parameters on the information loss. Fig. 12 illustrates this by showing the trade-off between the disclosure risk and data utility of a hypothetical dataset. The triangle represents the original data with full utility and a certain level of disclosure risk, which is too high for disclosure. The square represents no release of microdata. Although there is no risk of disclosure, there is also no utility from the data for users since no data is released. The points in between represent the result of applying different SDC methods with different parameter specifications. We would select the SDC method corresponding to the point, which maximizes the utility, while keeping disclosure risk at an acceptable level.
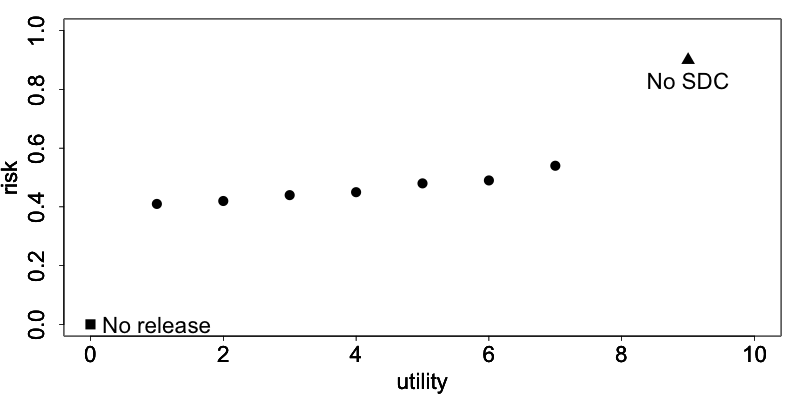
Fig. 12 The trade-off between risk and utility in a hypothetical dataset
In the following sections, we first propose general utility measures independent of data use, and later present an example of a specific measure useful to measure information loss with respect to specific data uses. Finally, we show how to visualize changes in the data caused by anonymization and discuss the selection of utility measures for a particular dataset.
General utility measures for continuous and categorical variables¶
General or generic measures of information loss can be divided into those comparing the actual values of the raw and anonymized data, and those comparing statistics from both datasets. All measures are a posteriori, since they measure utility after anonymization and require both the data before and after the anonymization process. General utility measures are different for categorical and continuous variables.
General utility measures for categorical variables¶
Number of missing values¶
An informative measure is to compare the number of missing values in the data. Missing values are often introduced after suppression and more suppressions indicate a higher degree of information loss. After using the local suppression function on an sdcMicro object, the number of suppressions for each categorical key variable can be retrieved with the print() function, which is illustrated in Listing 39 [2]. The argument ‘ls’ in the print() function stands for local suppression. The output shows both the absolute and relative number of suppressions.
1 2 3 4 5 6 7 8 9 10 11 | sdcInitial <- localSuppression(sdcInitial, k = 5, importance = NULL) print(sdcInitial, 'ls') ## Local Suppression: ## KeyVar | Suppressions (#) | Suppressions (%) ## URBRUR | 0 | 0.000 ## REGION | 81 | 4.050 ## RELIG | 0 | 0.000 ## MARITAL | 0 | 0.000 ## --------------------------------------------------------------------------- |
More generally, it is possible to count and compare the number of missing values in the original data and the treated data. This can be useful to see the proportional increase in the number of missing values. Missing values can also have other sources, such as nonresponse. Listing 40 shows how to display the number of missing values for each of the categorical key variables in an sdcMicro object. Here it is assumed that all missing values are coded ‘NA’. If the missing values are not coded ‘NA’, but instead another value, it is possible to use the alternative missing values code. The results agree with the number of missing values introduced by local suppression in the previous example, but also shows that the variable “RELIG” has 1,000 missing values in the original data.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | # Store the names of all categorical key variables in a vector namesKeyVars <- names(sdcInitial@manipKeyVars) # Matrix to store the number of missing values (NA) before and after anonymization NAcount <- matrix(NA, nrow = 2, ncol = length(namesKeyVars)) colnames(NAcount) <- c(paste0('NA', namesKeyVars)) # column names rownames(NAcount) <- c('initial', 'treated') # row names # NA count in all key variables (NOTE: only those coded NA are counted) for(i in 1:length(namesKeyVars)) { NAcount[1, i] <- sum(is.na(sdcInitial@origData[,namesKeyVars[i]])) NAcount[2, i] <- sum(is.na(sdcInitial@manipKeyVars[,i])) } # Show results NAcount ## NAURBRUR NAREGION NARELIG NAMARITAL ## initial 0 0 1000 51 ## treated 0 81 1000 51 |
Number of records changed¶
Another useful statistic is the number of records changed per variable. These can be counted in a similar way as the missing values and include suppressions (i.e., changes to missing/’NA’ in R). The number of records changed gives a good indication of the impact of the anonymization methods on the data. Listing 41 illustrates how to compute the number of records changed for the PRAMmed variables.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | # Store the names of all pram variables in a vector namesPramVars <- names(sdcInitial@manipPramVars) # Dataframe to save the number of records changed recChanged <- rep(0, length(namesPramVars)) names(recChanged) <- c(paste0('RC', namesPramVars)) # Count number of records changed for(j in 1:length(namesPramVars)) # for all key variables { comp <- sdcInitial@origData[namesPramVars[j]] != sdcInitial@manipPramVars[namesPramVars[j]] temp1 <- sum(comp, na.rm = TRUE) # all changed variables without NAs temp2 <- sum(is.na(comp)) # if NA, changed, unless NA initially temp3 <- sum(is.na(sdcInitial@origData[namesPramVars[j]]) + is.na(sdcInitial@manipPramVars[namesPramVars[j]])==2) # both NA, no change, but counted in temp2 recChanged[j] <- temp1 + temp2 - temp3 } # Show results recChanged ## RCWATER RCROOF RCTOILET ## 125 86 180 |
Comparing contingency tables¶
A useful way to measure information loss in categorical variables is to compare univariate tabulations and, more interestingly, contingency tables (also cross tabulations or two-way tables) between pairs of variables. To maintain the analytical validity of a dataset, the contingency tables should stay approximately the same. The function table() produces contingency tables of one or more variables. Listing 42 creates a contingency table of the variables “REGION” and “URBRUR”. We observe small differences between the tables before and after anonymization.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # Contingency table (cross tabulation) of the variables region and urban/rural table(sdcInitial@origData[, c('REGION', 'URBRUR')]) # before anonymization ## URBRUR ## REGION 1 2 ## 1 235 89 ## 2 261 73 ## 3 295 76 ## 4 304 71 ## 5 121 139 ## 6 100 236 table(sdcInitial@manipKeyVars[, c('REGION', 'URBRUR')]) # after anonymization ## URBRUR ## REGION 1 2 ## 1 235 89 ## 2 261 73 ## 3 295 76 ## 4 304 71 ## 5 105 130 ## 6 79 201 |
DoTo01b propose a Contingency Table-Based Information Loss (CTBIL) measure, which quantifies the distance between the contingency tables in the original and treated data. Alternatively, visualizations of the contingency table with mosaic plots can be used to compare the impact of anonymization methods on the tabulations and contingency tables (see the Section Mosaic plots).
General utility measures for continuous variables¶
Statistics: mean, covariance, correlation¶
The statistics characterizing the dataset should not change after the anonymization. Examples of such statistics are the mean, variance, and covariance and correlation structure of the most important variables in the dataset. Other statistics characterizing the data include the principal components and the loadings. DoTo01b give an overview of statistics that can be considered. In order to evaluate the information loss caused by the anonymization, one should compare the appropriate statistics for continuous variables computed from the data before and after anonymization. There are several ways to evaluate the loss of utility with respect to the changes in these statistics, for instance, by comparing means and (co-)variances in the data or comparing the (multivariate) distributions of the data. Especially changes in the correlations gives valuable information on the validity of the data for regressions. Functions from the R base package or any other statistical package can be used to do this. Following are a few examples in R.
To compute the mean of each numerical variable we use the function colMeans(). To ignore missing values, it is necessary to use the option na.rm = TRUE. “numVars” is a vector with the names of the numerical variables. Listing 43 shows how to compute the means for all numeric variables. The untreated data is extracted from the ‘origData’ slot of the sdcMicro object and the anonymized data from the ‘manipNumVars’ slot, which contains the manipulated numeric variables. We observe small changes in each of the three variables.
1 2 3 4 5 6 7 8 9 | # untreated data colMeans(sdcInitial@origData[, numVars], na.rm = TRUE) ## INC INCRMT INCWAGE ## 479.7710 961.0295 1158.1330 # anonymized data colMeans(sdcInitial@manipNumVars[, numVars], na.rm = TRUE) ## INC INCRMT INCWAGE ## 489.6030 993.8512 1168.7561 |
In the same way, one can compute the covariance and correlation matrices of the numerical variables in the sdcMicro object from the untreated and anonymized data. This is shown in Listing 44. We observe that the variance of each variable (the diagonal elements in the covariance matrix) have increased by the anonymization. These functions also allow computing confidence intervals in the case of samples. The means and covariances of subsets in the data also should not differ. An example is the mean of income by gender, by age group or by region. These characteristics of the data are important for analysis.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | # untreated data cov(sdcInitial@origData[, numVars]) ## INC INCRMT INCWAGE ## INC 1645926.1 586975.6 2378901 ## INCRMT 586975.6 6984502.3 1664257 ## INCWAGE 2378900.7 1664257.4 16169878 cor(sdcInitial@origData[, numVars]) ## INC INCRMT INCWAGE ## INC 1.0000000 0.1731200 0.4611241 ## INCRMT 0.1731200 1.0000000 0.1566028 ## INCWAGE 0.4611241 0.1566028 1.0000000 # anonymized data cov(sdcInitial@manipNumVars[, numVars]) ## INC INCRMT INCWAGE ## INC 2063013.1 649937.5 2382447 ## INCRMT 649937.5 8566169.1 1778985 ## INCWAGE 2382447.4 1778985.1 19925870 cor(sdcInitial@manipNumVars[, numVars]) ## INC INCRMT INCWAGE ## INC 1.0000000 0.1546063 0.3715897 ## INCRMT 0.1546063 1.0000000 0.1361665 ## INCWAGE 0.3715897 0.1361665 1.0000000 |
DoTo01b propose several measures for the discrepancy between the covariance and correlation matrices. These measures are based on the mean squared error, the mean absolute error or the mean variation of the individual cells. We refer to DoTo01b for a complete overview of these measures.
IL1s information loss measure¶
Alternatively, we can also compare the actual data and quantify the distance between the original dataset \(X\) and the treated dataset \(Z\). Here \(X\) and \(Z\) contain only continuous variables. YaWC02 introduce the distance measure IL1s, which is the sum of the absolute distances between the corresponding observations in the raw and anonymized datasets, which are standardized by the standard deviation of the variables in the original data. For the continuous variables in the dataset, the IL1s measure is defined as
where \(p\) is the number of continuous variables; \(n\) is the number of records in the dataset; \(x_{\text{ij}}\) and \(z_{\text{ij}}\), respectively, are the values before and after anonymization for variable \(j\) and individual \(i\); and \(S_{j}\) is the standard deviation of variable \(j\) in the original data (YaWC02).
When using sdcMicro, the IL1s data utility measure can be computed for all numerical quasi-identifiers with the function dUtility(), which is illustrated in Listing 45. If required, the measure can also be computed on subsets of the complete set of numerical quasi-identifiers. The function is called dUtility(), but returns a measure of information loss. The result is saved in the utility slot of the sdcMicro object. Listing 45 also illustrates how to call the result.
1 2 3 4 5 6 7 8 9 10 11 12 | # Evaluating IL1s measure for all variables in the sdcMicro object sdcInitial sdcInitial <- dUtility(sdcInitial) # Calling the result of IL1s sdcInitial@utility$il1 ## [1] 0.2203791 # IL1s for a subset of the numerical quasi-identifiers subset <- c('INCRMT', 'INCWAGE', 'INCFARMBSN') dUtility(obj = sdcInitial@origData[,subset], xm = sdcInitial@manipNumVars[,subset], method = 'IL1') ## [1] 0.5641103 |
The measure is useful for comparing different methods. The smaller the value of the measure, the closer the values are to the original values and the higher the utility.
Note
This measure is related to risk measures based on distance and intervals (see the Section Risk measures for continuous variables).
The greater the distance between the original and anonymized values, the lower the data utility. Greater distance, however, also reduces the risk of re-identification.
Eigenvalues¶
Another way to evaluate the information loss is to compare the robust eigenvalues of the data before and after anonymization. Listing 46 illustrates how to use this approach with sdcMicro. Here “contVars” is a vector with the names of the continuous variables in which we are interested. “obj” is the argument that specifies the untreated data and “xm” is the argument that specifies the anonymized data. The function’s output is the difference in eigenvalues. Therefore, the minimum value is 0. Again, the main use is to compare different methods. The greater the value, the greater the changes in the data and the information loss.
1 2 3 4 5 6 7 8 9 | # Comparison of eigenvalues of continuous variables dUtility(obj = sdcInitial@origData[,contVars], xm = sdcInitial@manipNumVars[,contVars], method = 'eigen') ## [1] 2.482948 # Comparison of robust eigenvalues of continuous variables* dUtility(obj = sdcInitial@origData[,contVars], xm = sdcInitial@manipNumVars[,contVars], method = 'robeigen') ## [1] -4.297621e+14 |
Utility measures based on the end user’s needs¶
Not all needs and uses of a certain dataset can be inventoried. Nevertheless, some types of data have similar uses or important characteristics, which can be evaluated before and after anonymization. Examples of such “benchmarking indicators” (TMKC14) are different for each dataset. Examples include poverty measures for income datasets and school attendance ratios. Often ideas for selecting such indicators come from the reports data users publish based on previously released microdata.
The approach is to compare the indicators calculated on the untreated data and the data after anonymization with different methods. If the differences between the indicators are not too large, the anonymized dataset can be released for use by researchers. It should be taken into account that indicators calculated on samples are estimates with a certain variance and confidence interval. Therefore, for sample data, it is more informative to compare the overlap of confidence intervals and/or to evaluate whether the point estimate calculated after anonymization is contained within the confidence interval of the original estimate. Examples of benchmark indicators and their confidence intervals and how to compute these in R are included in the case studies in these guidelines. Here we give the example of the GINI coefficient.
The GINI coefficient is a measure of statistical dispersion, which is often used to measure inequality in income. A way to measure the information loss in income data is to compare the income distribution, which can be easily done by comparing the GINI coefficients. Several R packages have functions to compute the GINI coefficient. We chose the laeken package, which computes the GINI coefficient as the area between the 45-degree line and the Lorenz curve. To use the gini() function, we first have to install and load the laeken library. To calculate the GINI coefficient for the variable income, we use the sample weights in the data. This is shown in Listing 47. The GINI coefficient of sample data is a random variable. Therefore, it is useful to construct a confidence interval around the coefficient to evaluate the significance of any change in the coefficient after anonymization. The gini() function computes a 1-alpha confidence interval for the GINI coefficient by using bootstrap.
1 2 3 4 5 6 7 8 9 | # Gini coefficient before anonymization gini(inc = sdcInitial@origData[selInc,'INC'], weights = curW[selInc], na.rm = TRUE)$value # before ## [1] 34.05928 # Gini coefficient after anonymization gini(inc = sdcInitial@manipNumVars[selInc,'INC'], weights = curW[selInc], na.rm = TRUE)$value # after ## [1] 67.13218 |
Regression¶
Besides comparing covariance and correlation matrices, regressions are a useful tool to evaluate whether the structure in the data is maintained after anonymization. By comparing regressions parameters, it is also possible to compare relations between non-continuous variables (e.g., by introducing dummy variables or regression with ordinal variables). If it is known for what purpose and in what field the data is used, common regressions can be used to compare the change in coefficients and confidence intervals.
An example of using regression to evaluate the data utility in income data is the Mincer equation. The Mincer equation explains earnings as a function of education and experience while controlling for other variables. The Mincer equation is often used to evaluate the gender pay gap and gender wage inequality by including a gender dummy. Here we show how to evaluate the impact of anonymization methods on the gender coefficient. We regress the log income on a constant, a gender dummy, years of education, years of experience, years of experience squared and other factors influencing wage.
The parameter of interest here is \(\beta_{1}\), the effect of gender on the log wage. X is a matrix with several other factors influencing wage and \(\beta\) the coefficients of these factors. Listing 48 illustrates how to run a Mincer regression in R using the function lm() and evaluate the coefficients and confidence intervals around the coefficients. We run the regression as specified for paid employees with a positive wage in the age groups 15 – 65 years.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | # Mincer equation variables before anonymization Mlwage <- log(sdcMincer@origData$wage) # log wage # TRUE if 'paid employee', else FALSE or NA Mempstat <- sdcMincer@origData$empstat=='Paid employee' Mage <- sdcMincer@origData$age # age in years Meducy <- sdcMincer@origData$educy # education in years Mexp <- sdcMincer@origData$exp # experience in years Mexp2 <- Mexp^2 # squared experience Mgender <- sdcMincer@origData$gender # gender dummy Mwgt <- sdcMincer@origData$wgt # weight variable for regression MfileB <- as.data.frame(cbind(Mlwage, Mempstat, Mage, Meducy, Mexp, Mexp2, Mgender, Mwgt)) # Mincer equation variables after anonymization Mlwage <- log(sdcMincer@manipNumVars$wage) # log wage Mempstat <- sdcMincer@manipKeyVars$empstat=='Paid employee' # TRUE if 'paid employee', else FALSE or NA Mage <- sdcMincer@manipKeyVars$age # age in years Meducy <- sdcMincer@manipKeyVars$educy # education in years Mexp <- sdcMincer@manipKeyVars$exp # experience in years Mexp2 <- Mexp^2 # squared experience Mgender <- sdcMincer@manipKeyVars$gender # gender dummy Mwgt <- sdcMincer@origData$wgt # weight variable for regression MfileA <- as.data.frame(cbind(Mlwage, Mempstat, Mage, Meducy, Mexp, Mexp2, Mgender, Mwgt)) # Specify regression formula Mformula <- 'Mlwage ~ Meducy + Mexp + Mexp2 + Mgender' # Regression Mincer equation mincer1565B <- lm(Mformula, data = subset(MfileB, MfileB$Mage >= 15 & MfileB$Mage <= 65 & MfileB$Mempstat==TRUE & MfileB$Mlwage != -Inf), na.action = na.exclude, weights = Mwgt) # before mincer1565A <- lm(Mformula, data = subset(MfileA, MfileA$Mage >= 15 & MfileA$Mage <= 65 & MfileA$Mempstat==TRUE & MfileA$Mlwage != -Inf), na.action = na.exclude, weights = Mwgt) # after # The objects mincer1565B and mincer1565A contain the results of the regressions before and after anonymization mincer1565B$coefficients # before ## (Intercept) Meducy Mexp Mexp2 Mgender ## 3.9532064886 0.0212367075 0.0255962570 -0.0005682651 -0.4931289413 mincer1565A$coefficients # after ## (Intercept) Meducy Mexp Mexp2 Mgender ## 4.0526250282 0.0141090329 0.0326711056 -0.0007605492 -0.5393641862 # Compute the 95 percent confidence interval confint(obj = mincer1565B, level = 0.95) # before ## 2.5 % 97.5 % ## (Intercept) 3.435759991 4.4706529860 ## Meducy -0.018860497 0.0613339120 ## Mexp 0.004602597 0.0465899167 ## Mexp2 -0.000971303 -0.0001652273 ## Mgender -0.658085143 -0.3281727396 confint(obj = mincer1565A, level = 0.95) # after ## 2.5 % 97.5 % ## (Intercept) 3.46800378 4.6372462758 ## Meducy -0.03305743 0.0612754964 ## Mexp 0.01024867 0.0550935366 ## Mexp2 -0.00119162 -0.0003294784 ## Mgender -0.71564602 -0.3630823543 |
If the new estimates fall within the original confidence interval and the new and original confidence intervals are greatly overlapping, the data can be considered valid for this type of regression after anonymization. Fig. 13 shows the point estimates and confidence intervals for the gender coefficient in this trade-off for a sample income dataset and several SDC methods and parameters. The red dot and confidence bar (on the top) correspond to the estimates for the untreated data, whereas the other confidence bars correspond to the respective SDC methods and different parameters. The anonymization reduces the number of expected re-identifications in the data (left axis) and the point estimates and confidence intervals vary greatly for the different SDC methods. We would choose a method, which reduces the expected number of identifications, while not changing the gender coefficient and having a great overlap of the confidence interval with the confidence interval estimated from the original data.
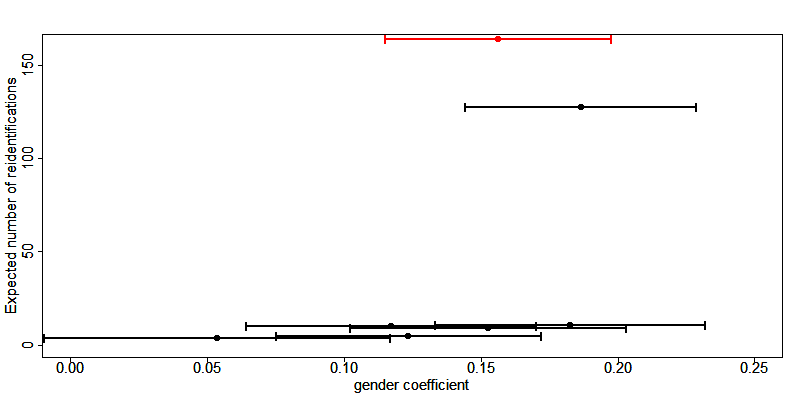
Fig. 13 Effect of anonymization on the point estimates and confidence interval of the gender coefficient in the Mincer equation
Assessing data utility with the help of data visualizations (in R)¶
The use of graphs and other visualization techniques is a good way to assess at a glance how much the data have changed after anonymization, and can aid the selection of appropriate anonymization techniques for the data. Visualizations can be a useful tool to assess the impact on data utility of anonymization methods and helps choose among anonymization methods. The software package R provides several functions and packages that can help visualize the results of anonymization. This section lists a few of these functions and packages and provides code examples to illustrate how to implement them. We present the following visualizations:
- histograms and density plots
- boxplots
- mosaic plots
To make appropriate visualizations, we need to use the raw data and the anonymized data. When using an sdcMicro object for the anonymization process, the raw data are stored in the “origData” slot of the object and the anonymized variables are in the slots “manipKeyVars”, “manipPramVars”, “manipNumVars” and “manipStrataVar” slots. See the Section Objects of class sdcMicroObj for more information on sdcMicro objects, slots and how to access slots.
Histograms and density plots¶
Histograms and density plots are useful for quick comparisons of variable distribution before and after anonymization. The advantage of histograms is that the results are exact. Visualization depends on the bin widths and the start point of the first bin, however. Histograms can be used for continuous and semi-continuous variables. Density plots display the kernel density of the data; therefore, the plot depends on the kernel that is chosen and whether the data fits the kernel well. Nevertheless, density plots are a good tool to illustrate the change of values and value ranges of continuous variables.
Histograms can be plotted with function hist() and kernel densities with the functions plot() and density() in R. Listing 49 provides examples of how to use these functions to illustrate the changes in the variable ”INC”, an income variable. The function hist() needs as argument the break points for the histogram. The results are shown in Fig. 14 and Fig. 15. The histograms and density plots give a clear indication how the values have changed: the variability of the data has increased and the shape of the distribution has changed.
Note
The vertical axes of the histograms have different scales.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # Plot histograms # Plot histogram before anonymization hist(sdcInitial@origData$INC, breaks = (0:180)*1e2, main = "Histogram income - original data") # Plot histogram after anonymization (noise addition) hist(sdcInitial@manipNumVars$INC, breaks = (-20:190)*1e2, main = "Histogram income - anonymized data") # Plot densities # Plot original density curve plot(density(sdcInitial@origData$INC), xlim = c(0, 8000), ylim = c*(0, 0.006), main = "Density income", xlab = "income") par (new = TRUE) # Plot density curve after anonymization (noise addition) plot(density(sdcInitial@manipNumVars$INC), xlim = c(0, 8000), ylim = c(0, 0.006), main = "Density income", xlab = "income") |
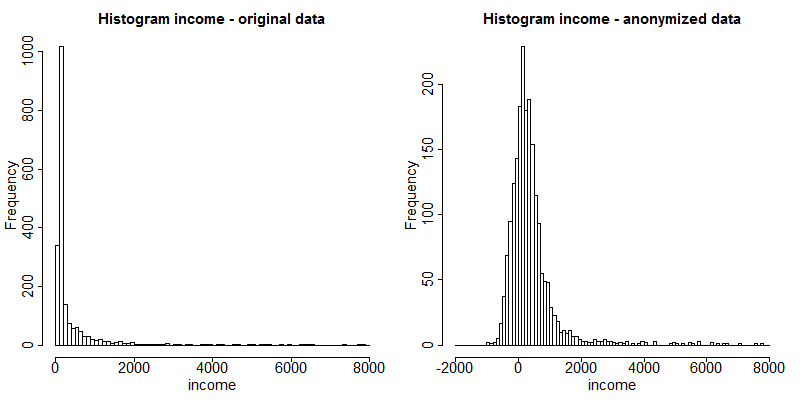
Fig. 14 Histograms of income before and after anonymization
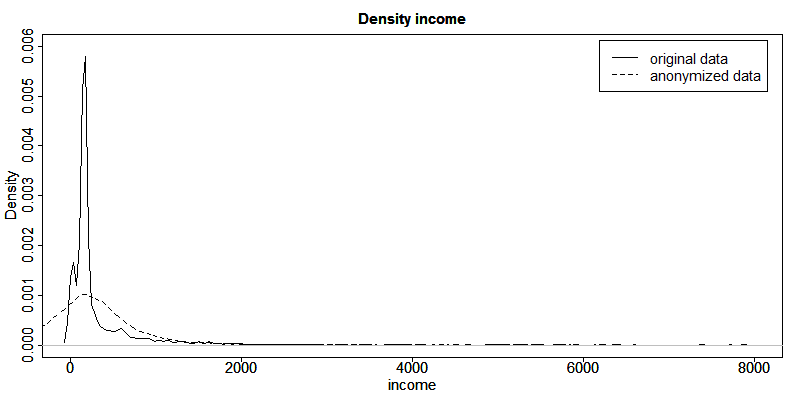
Fig. 15 Density plots of income before and after anonymization
Box plots¶
Box plots give a quick overview of the changes in the spread and outliers of continuous variables before and after anonymization. Listing 50 shows how to generate box plots in R with the function boxplot(). The result in Fig. 16 shows an example for an expenditure variable after adding noise. The box plot shows clearly that the variability in the expenditure variable increased as a result of the anonymization methods applied.
1 2 3 | boxplot(sdcObj@origData$TOTFOOD, sdcObj@manipNumVars$TOTFOOD, xaxt = 'n', ylab = "Expenditure") axis(1, at = c(1,2), labels = c('before', 'after')) |
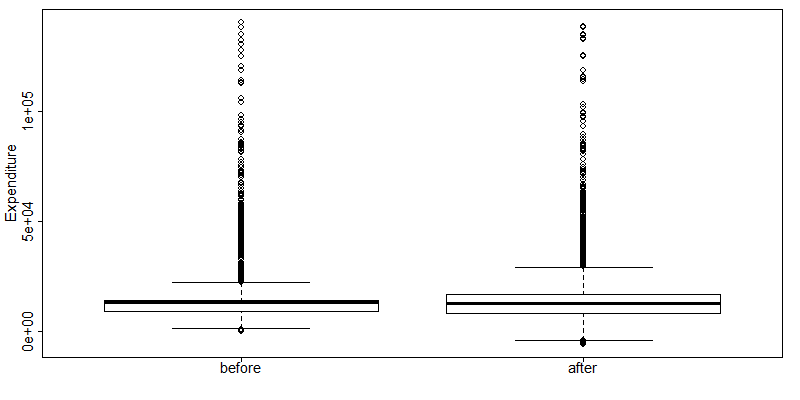
Fig. 16 Example of box plots of an expenditure variable before and after anonymization
Mosaic plots¶
Univariate and multivariate mosaic plots are useful for showing changes in the tabulations of categorical variables, especially when comparing several “scenarios” next to one another. A scenario here refers to the choice of anonymization methods and their parameters. With mosaic plots we can, for instance, quickly see the effect of different levels of \(k\)-anonymity or differences in the importance vectors in the local suppression algorithm (see the Section Local suppression).
We illustrate the changes in tabulations with an example of the variable “WATER” before and after applying PRAM. We can use mosaic plots to quickly see the changes for each category. Listing 51 shows the code in R. The function mosaicplot() is available in base R. To plot a tabulation, first the tabulation must be made with the table() function. To show the labels in the mosaicplot(), we change the class of the variables to ‘factor’ (see the Section Classes in R). Looking at the mosaic plot in Fig. 17 we see invariant PRAM has virtually no influence on the univariate distribution.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # Collecting data of variable WATER before and after anonymization, # assigning factor levels for labels in plot dataWater <- t(cbind(table(factor(sdcHH@origData$WATER, levels = c(1, 2, 3, 4, 5, 6, 7, 8, 9), labels = c("Pipe (own tap)", "Public standpipe", "Borehole", "Wells (protected)", "Wells (unprotected)", "Surface water", "Rain water", "Vendor/truck", "Other"))), table(factor(sdcHH@manipPramVars$WATER, levels = c(1,2, 3, 4, 5, 6, 7, 8, 9), labels = c("Pipe (own tap)", "Public standpipe", "Borehole", "Wells (protected)", "Wells (unprotected)", "Surface water", "Rain water", "Vendor/truck","Other"))))) rownames(dataWater) <- c("before", "after") # Plotting mosaic plot mosaicplot(dataWater, main = "", color = 2:10, las = 2) |
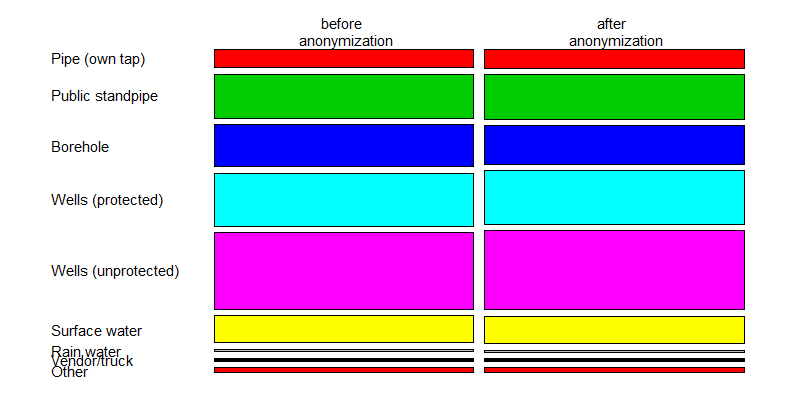
Fig. 17 Mosaic plot to illustrate the changes in the WATER variable
We use the variables “gender” and “relationship status” to illustrate the use of mosaic plots for the illustration of changes in univariate tabulations introduced by several sets of anonymization methods. Table 20 provides the methods applied in each scenario. Scenario 0, the base scenario, shows the original categories of the gender and relationship status variables, while scenarios 1 to 6 show shifts in the categories after applying different anonymization techniques. Table 6.1 provides a description of the anonymization methods used in each scenario. In total we visualize the impact of six different sets of anonymization methods. We can use mosaic plots to quickly see which set of methods has what impact on the gender and relationship status variables, which can be used to select the best scenario. Looking at the mosaic plots in Fig. 18 , we see that scenarios 2, 5 and 6 give the smallest changes for the gender variable and scenarios 3 and 4 for the relationship status variable.
| Scenario | Description of anonymization methods applied |
|---|---|
| 0 (base) | Original data, no treatment |
| 1 | Recode age (five-year intervals), plus local suppression (required k = 3, high importance on water, toilet and literacy variables) |
| 2 | Recode age (five-year intervals), plus local suppression (required k = 5, no importance vector) |
| 3 | Recode age (five-year intervals), plus local suppression (required k = 3, high importance on toilet), while also recoding region, urban, education level and occupation variables |
| 4 | Recode age (five-year steps), plus local suppression (required k = 5, high importance on water, toilet and literacy), while also recoding region, urban, education level and occupation variables |
| 5 | Recode age (five-year intervals), plus local suppression (required k = 3, no importance vector), microaggregation (wealth index), while also recoding region, urban, education level and occupation variables |
| 6 | Recode age (five-year intervals) plus local suppression (required k=3, no importance vector), PRAM literacy, while also recoding region, urban, education level and occupation variables |
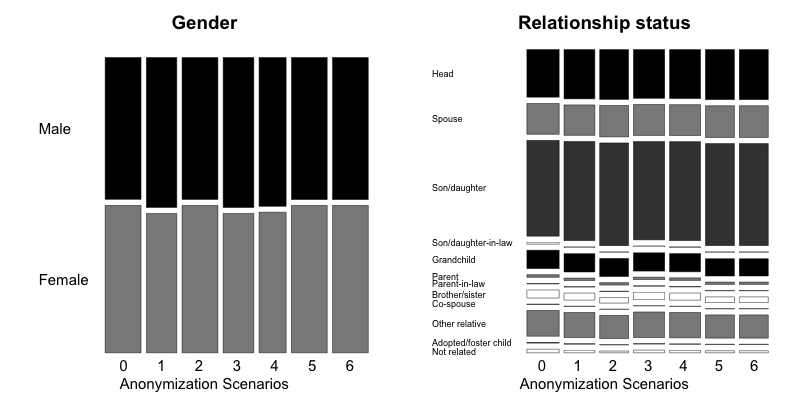
Fig. 18 Comparison of treated vs. untreated gender and relationship status variables with mosaic plots
As we discussed in the Section `PRAM (Post RAndomization Method) <anon_methods.html# PRAM (Post RAndomization Method)`__ , invariant PRAM preserves the univariate distributions. Therefore, in this case it is more interesting to look at the multivariate mosaic plots. Mosaic plots are also a powerful tool to show changes in cross-tabulations/contingency tables. Listing 52 shows how to generate mosaic plots for two variables. To compare the changes, we need to compare two different plots. Fig. 19 and Fig. 20 illustrate that (invariant) PRAM does not preserve the two-way tables in this case.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # Before anonymization: contingency table and mosaic plot ROOFTOILETbefore <- t(table(factor(sdcHH@origData$ROOF, levels = c(1,2, 3, 4, 5, 9), labels = c("Concrete/cement/ \n brick/stone", "Wood", "Bamboo/thatch", "Tiles/shingles", "Tin/metal sheets", "Other")), factor(sdcHH@origData$TOILET, levels = c(1,2, 3, 4, 9), labels = c("Flush \n toilet", "Improved \n pit \n latrine", "Pit \n latrine", "No \n facility", "Other")))) mosaicplot(ROOFTOILETbefore, main = "", las = 2, color = 2:6) # After anonymization: contingency table and mosaic plot ROOFTOILETafter <- t(table(factor(sdcHH@manipPramVars$ROOF, levels = c(1,2, 3, 4, 5, 9), labels = c("Concrete/cement/ \n brick/stone", "Wood", "Bamboo/thatch", "Tiles/shingles", "Tin/metal sheets", "Other")), factor(sdcHH@manipPramVars$TOILET, levels = c(1,2, 3, 4, 9), labels = c("Flush \n toilet", "Improved \\n pit \n latrine", "Pit \n latrine", "No \n facility", "Other")))) mosaicplot(ROOFTOILETafter, main = "", las = 2, color = 2:6) |
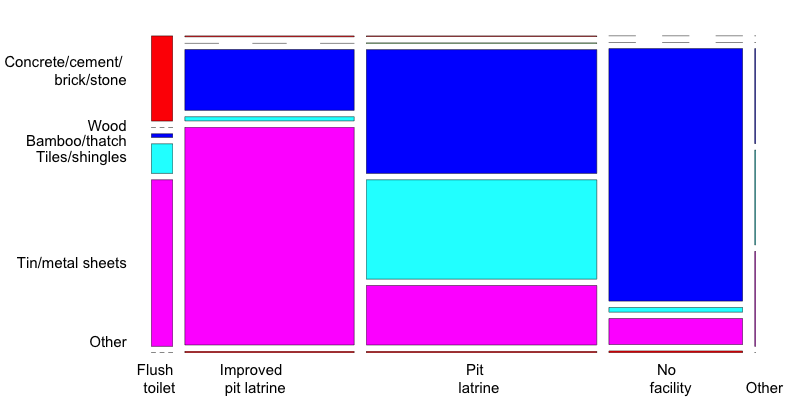
Fig. 19 Mosaic plot of the variables ROOF and TOILET before anonymization
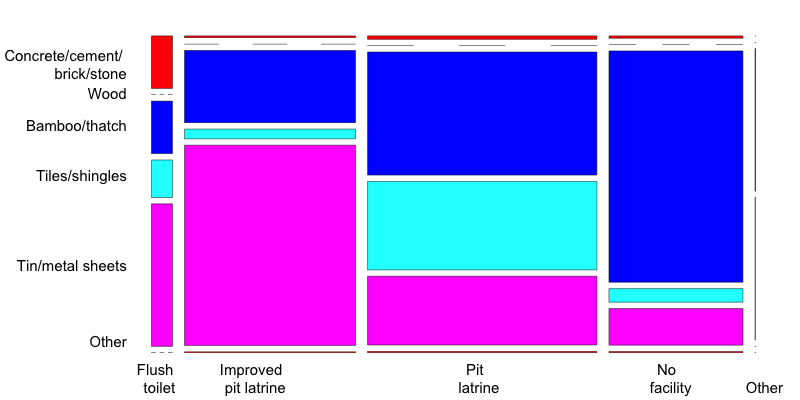
Fig. 20 Mosaic plot of the variables ROOF and TOILET after anonymization
Choice of utility measure¶
Besides the users’ requirements on the data, the utility measures should be chosen in accordance with the variable types and anonymization methods employed. The employed utility measures can be a combination of both general and user-specific measures. As discussed earlier, different utility measures should be used for continuous and categorical data. Furthermore, some utility measures are not informative after certain anonymization methods have been applied. For example, after applying perturbative methods that interchange data values, comparing values directly is not useful because they will give the impression of high levels of information loss. In such cases, it is more informative to look at means, covariances and benchmarking indicators that can be computed from the data. Furthermore, it is important not only to focus on the characteristics of variables one by one, but also on the interactions between variables. This can be done by cross-tabulations and regressions. In general, when anonymizing sampled data, it is advisable to compute confidence intervals around estimates to interpret the magnitude of changes.
Recommended Reading Material on Measuring Utility and Information Loss
A.G. De Waal and L.C.R.J. Willenborg. 1999. “Information Loss through Global Recoding and Local Suppression” In Netherlands Official Statistics: Special Issue on SDC, 14, 17-10.
J. Domingo-Ferrer, J.M. Mateo-Sanz and V. Torra. 2001. “Comparing SDC Methods for Microdata on the basis of Information Loss and Disclosure Risk”. In Pre-proceedings of ETK-NTTS 2001 (vol. 2), 807-826. http://neon.vb.cbs.nl/casc/NTTSJosep.pdf
J. Domingo-Ferrer and V. Torra. 2001. “Disclosure Protection Methods and Information Loss for Microdata”. In P. Doyle, J.I. Lane, J.J.M. Theeuwes and L. Zayatz (eds.) Theory and Practical Applications for Statistical Agencies, 91-110, Amsterdam. http://crises-deim.urv.cat/webCrises/publications/bcpi/cliatpasa01Disclosure.pdf
| [1] | It is possible to release data files for different groups of users, e.g., PUF and SUF. All information in the less detailed file, however, must also be included in the more detailed file to prevent unintended disclosure. Datasets released in data enclaves can be customized for the user, since the risk that they will be combined with other version is zero. |
| [2] | Here the sdcMicro object “sdcIntial“ contains a dataset with 2,500 individuals and 103 variables. We selected three categorical quasi-identifiers: “URBRUR”, “REGION”, “RELIG” and “MARITAL” and several continuous quasi-identifiers relating to income and expenditure. To illustrate the utility loss, we also applied several SDC methods to this sdcMicro object, such as local suppression, PRAM and additive noise addition. |
References
| [DoTo01b] | Domingo-Ferrer, J., & Torra, V. (2001). Disclosure Protection Methods and Information Loss for Microdata. In P. Doyle, J. Lane, J. Theeuwes, & Z. L., Theory and Practical Applications for Statistical Agencies (pp. 91-110). Amsterdam. |
| [HDFG12] | Hundepool, A., Domingo-Ferrer, J., Franconi, L., Giessing, S., Nordholt, E. S., Spicer, K., et al. (2012). Statistical Disclosure Control. Chichester, UK: John Wiley & Sons Ltd. |
| [TMKC14] | Templ, M., Meindl, B., Kowarik, A., & Chen, S. (2014, August 1). Introduction to Statistical Disclosure Control (SDC). Retrieved July 9, 2018, from http://www.ihsn.org/home/software/disclosure-control-toolbox. |
| [YaWC02] | Yancey, W. W., Winkler, W. E., & Creecy, R. H. (2002). Disclosure Risk Assessment in Perturbative Microdata Protection. Research Report Series , Statistics 2002-01. |